
Bufferization for Mixed Linalg and ONNX Operations
Published:
1. Overview
When performing bufferization in ONNX-MLIR, problems can occur when we need to bufferize linalg and krnl simultaneously, because each dialect has a different method of bufferization.
linalg uses MLIR’s One-shot Bufferization1, while krnl uses the pass implemented in existing ONNX-MLIR for bufferization.
To solve this situation, we plan to implement it in the following way.
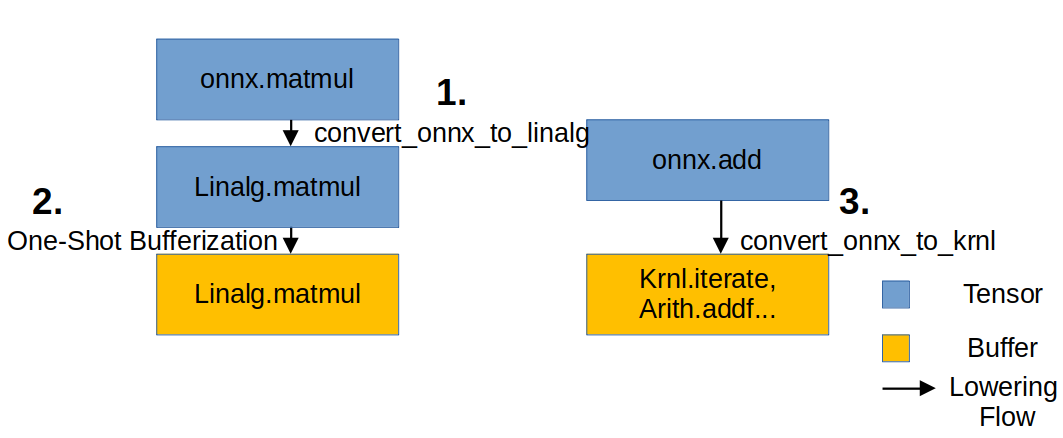 We will apply Lowering according to this figure. First, we lower
We will apply Lowering according to this figure. First, we lower onnx to linalg and apply One-shot Bufferization. At this time, existing onnx operations that were not converted to linalg do not have Bufferization applied. This is because these operations need to be lowered to krnl later. After applying One-Shot Bufferization, we bufferize the remaining onnx operations to krnl.
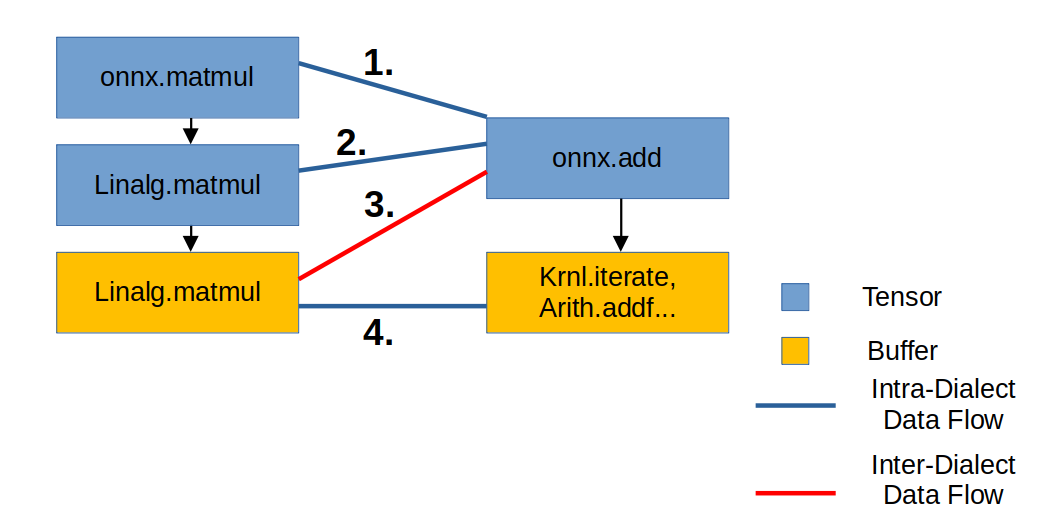 Each time we go through the above Lowering process, the IR structure is as follows. Rectangles represent IR, and lines connecting rectangles represent the connection state between IRs.
Each time we go through the above Lowering process, the IR structure is as follows. Rectangles represent IR, and lines connecting rectangles represent the connection state between IRs.
2. IR Lowering
[Input] Initial State: ONNX Tensor IR
func.func @test_full_pipeline(%arg0 : tensor<2x3xf32>, %arg1 : tensor<3x4xf32>, %arg2 : tensor<2x4xf32>) -> tensor<2x4xf32> {
%0 = "onnx.MatMul"(%arg0, %arg1) : (tensor<2x3xf32>, tensor<3x4xf32>) -> tensor<2x4xf32>
%1 = "onnx.Add"(%0, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %1 : tensor<2x4xf32>
}
Everything here is tensor. MatMul and Add are just mathematical operations, and it is not defined where they will be stored in memory.
[Step 1] Lowering to Linalg (Maintaining Tensor)
Command: --convert-onnx-to-linalg
func.func @test_full_pipeline(%arg0: tensor<2x3xf32>, %arg1: tensor<3x4xf32>, %arg2: tensor<2x4xf32>) -> tensor<2x4xf32> {
%cst = arith.constant 0.000000e+00 : f32
%0 = tensor.empty() : tensor<2x4xf32>
%1 = linalg.fill ins(%cst : f32) outs(%0 : tensor<2x4xf32>) -> tensor<2x4xf32>
%2 = linalg.matmul ins(%arg0, %arg1 : tensor<2x3xf32>, tensor<3x4xf32>) outs(%1 : tensor<2x4xf32>) -> tensor<2x4xf32>
%3 = "onnx.Add"(%2, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %3 : tensor<2x4xf32>
}
tensor.empty()was created, which acts as a “placeholder” that will becomememref.alloc()when bufferized later.- Everything is still
tensortype.
[Step 2] One-Shot Bufferization
Command: --one-shot-bufferize=allow-unknown-ops
func.func @test_full_pipeline(%arg0: tensor<2x3xf32>, %arg1: tensor<3x4xf32>, %arg2: tensor<2x4xf32>) -> tensor<2x4xf32> {
%0 = bufferization.to_buffer %arg1 : tensor<3x4xf32> to memref<3x4xf32, strided<[?, ?], offset: ?>>
%1 = bufferization.to_buffer %arg0 : tensor<2x3xf32> to memref<2x3xf32, strided<[?, ?], offset: ?>>
%cst = arith.constant 0.000000e+00 : f32
%alloc = memref.alloc() {alignment = 64 : i64} : memref<2x4xf32>
linalg.fill ins(%cst : f32) outs(%alloc : memref<2x4xf32>)
linalg.matmul ins(%1, %0 : memref<2x3xf32, strided<[?, ?], offset: ?>>, memref<3x4xf32, strided<[?, ?], offset: ?>>) outs(%alloc : memref<2x4xf32>)
%2 = bufferization.to_tensor %alloc : memref<2x4xf32> to tensor<2x4xf32>
%3 = "onnx.Add"(%2, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %3 : tensor<2x4xf32>
}
tensor.empty() disappeared and memref.alloc() appeared. Now the result of linalg.matmul is written directly to this allocated address. Also, with bufferization.to_buffer, we can treat the input tensor arguments as memref.
linalg.matmul wrote the result to a buffer, but the next onnx.Add still receives tensors as input. So we wrap the buffer back as a tensor with bufferization.to_tensor.
[Step 3] Krnl Lowering
Command: ... --convert-onnx-to-krnl
func.func @test_full_pipeline(%arg0: memref<2x3xf32>, %arg1: memref<3x4xf32>, %arg2: memref<2x4xf32>) -> memref<2x4xf32> {
// ... omitted ...
linalg.matmul ins(%3, %2 : ...) outs(%alloc : memref<2x4xf32>)
%4 = bufferization.to_tensor %alloc : memref<2x4xf32> to tensor<2x4xf32>
%5 = builtin.unrealized_conversion_cast %4 : tensor<2x4xf32> to memref<2x4xf32>
// onnx.Add is converted to concrete loops
krnl.iterate(%6#0, %6#1) with (...) {
%8 = krnl.load %5[%7#0, %7#1] : memref<2x4xf32> // Load from MatMul result buffer
%9 = krnl.load %arg2[%7#0, %7#1] : memref<2x4xf32>
%10 = arith.addf %8, %9 : f32
krnl.store %10, %alloc_3[...] : memref<2x4xf32>
}
return %alloc_3 : memref<2x4xf32>
}
The function signature has completely changed from tensor to memref. No more abstract tensors exist.
onnx.Add has been broken down into loops (krnl.iterate) and load/store operations (krnl.load, krnl.store) that hardware can understand.
unrealized_conversion_cast resolves temporary type mismatches. This will be removed by optimization passes later.
Series Posts
- Previous: Detailed Pipeline Stages with useLinalgPath Enabled and End-to-End Validation
- Next: Converting ONNX Conv to Linalg: conv_2d_nchw_fchw
Language: 한국어 (Korean)
https://mlir.llvm.org/docs/Bufferization/ ↩