
Mixed Linalg and ONNX Operations를 위한 Bufferization
Published:
1. 개요
ONNX-MLIR에서 bufferization을 수행할 때, linalg와 krnl으로 동시에 bufferization해야하는 경우 문제가 발생할 수 있습니다. 왜냐하면 각 dialect마다 bufferization하는 방법이 다르기 때문입니다.
linalg의 경우 MLIR의 One-shot Bufferization1으로, krnl은 기존 ONNX-MLIR에 구현되어 있는 패스로 bufferization합니다.
이런 상황을 해결하기 위해, 다음과 같은 방식으로 구현할 예정입니다.
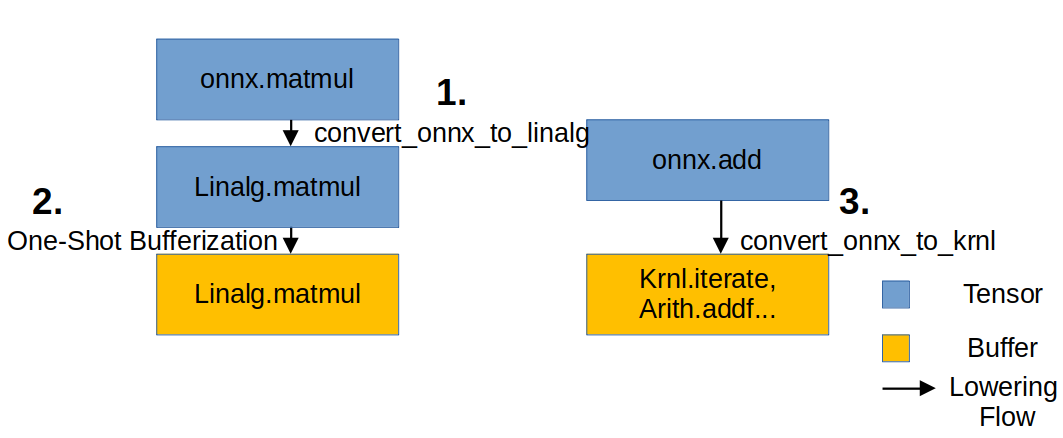 해당 figure대로 Lowering을 적용할 것입니다. 우선
해당 figure대로 Lowering을 적용할 것입니다. 우선 onnx를 linalg로 Lowering하고, One-shot Bufferization을 적용합니다. 이 때, linalg로 변환되지 않은 기존 onnx 연산은, Bufferization을 적용하지 않습니다. 왜냐하면 이 연산은 나중에 krnl으로 Lowering해야 하기 때문입니다. One-Shot Bufferization을 적용한 뒤, 남은 onnx 연산을 krnl으로 Bufferization합니다.
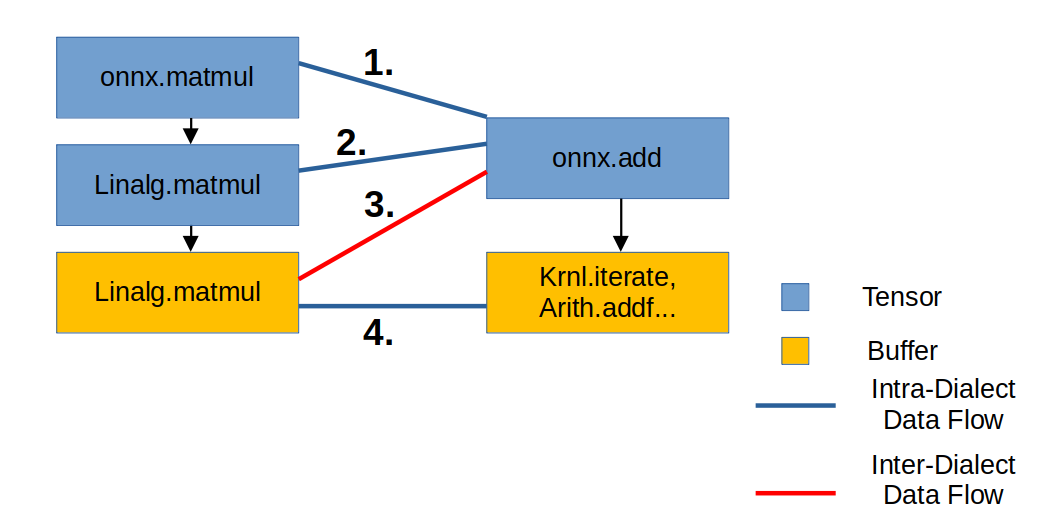 위의 Lowering 과정을 거칠 때마다, IR의 구조는 다음과 같습니다. 사각형은 IR, 사각형을 연결하는 선은 IR들의 연결 상태를 나타냅니다.
위의 Lowering 과정을 거칠 때마다, IR의 구조는 다음과 같습니다. 사각형은 IR, 사각형을 연결하는 선은 IR들의 연결 상태를 나타냅니다.
2. IR Lowering
[Input] 초기 상태: ONNX Tensor IR
func.func @test_full_pipeline(%arg0 : tensor<2x3xf32>, %arg1 : tensor<3x4xf32>, %arg2 : tensor<2x4xf32>) -> tensor<2x4xf32> {
%0 = "onnx.MatMul"(%arg0, %arg1) : (tensor<2x3xf32>, tensor<3x4xf32>) -> tensor<2x4xf32>
%1 = "onnx.Add"(%0, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %1 : tensor<2x4xf32>
}
여기서는 모든 것이 tensor입니다. MatMul과 Add는 수학적인 연산일 뿐, 어느 메모리에 저장될지는 정의되지 않았습니다.
[Step 1] Linalg로 Lowering (Tensor 유지)
명령어: --convert-onnx-to-linalg
func.func @test_full_pipeline(%arg0: tensor<2x3xf32>, %arg1: tensor<3x4xf32>, %arg2: tensor<2x4xf32>) -> tensor<2x4xf32> {
%cst = arith.constant 0.000000e+00 : f32
%0 = tensor.empty() : tensor<2x4xf32>
%1 = linalg.fill ins(%cst : f32) outs(%0 : tensor<2x4xf32>) -> tensor<2x4xf32>
%2 = linalg.matmul ins(%arg0, %arg1 : tensor<2x3xf32>, tensor<3x4xf32>) outs(%1 : tensor<2x4xf32>) -> tensor<2x4xf32>
%3 = "onnx.Add"(%2, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %3 : tensor<2x4xf32>
}
tensor.empty()가 생성되었는데, 이는 나중에 버퍼화될 때memref.alloc()이 될 “자리 표시자” 역할을 합니다.- 아직은 모두
tensor타입입니다.
[Step 2] One-Shot Bufferization 수행
명령어: --one-shot-bufferize=allow-unknown-ops
func.func @test_full_pipeline(%arg0: tensor<2x3xf32>, %arg1: tensor<3x4xf32>, %arg2: tensor<2x4xf32>) -> tensor<2x4xf32> {
%0 = bufferization.to_buffer %arg1 : tensor<3x4xf32> to memref<3x4xf32, strided<[?, ?], offset: ?>>
%1 = bufferization.to_buffer %arg0 : tensor<2x3xf32> to memref<2x3xf32, strided<[?, ?], offset: ?>>
%cst = arith.constant 0.000000e+00 : f32
%alloc = memref.alloc() {alignment = 64 : i64} : memref<2x4xf32>
linalg.fill ins(%cst : f32) outs(%alloc : memref<2x4xf32>)
linalg.matmul ins(%1, %0 : memref<2x3xf32, strided<[?, ?], offset: ?>>, memref<3x4xf32, strided<[?, ?], offset: ?>>) outs(%alloc : memref<2x4xf32>)
%2 = bufferization.to_tensor %alloc : memref<2x4xf32> to tensor<2x4xf32>
%3 = "onnx.Add"(%2, %arg2) : (tensor<2x4xf32>, tensor<2x4xf32>) -> tensor<2x4xf32>
return %3 : tensor<2x4xf32>
}
tensor.empty()가 사라지고 memref.alloc()이 등장했습니다. 이제 linalg.matmul의 결과는 이 할당된 주소에 직접 쓰여집니다. 그리고, bufferization.to_buffer으로, 입력받은 tensor 인자들을 memref로 취급할 수 있게 합니다.
linalg.matmul은 버퍼에 결과를 썼지만, 다음에 올 onnx.Add는 아직 텐서를 입력값으로 받습니다. 그래서 bufferization.to_tensor로, 버퍼를 다시 텐서처럼 래핑합니다.
[Step 3] Krnl Lowering
명령어: ... --convert-onnx-to-krnl
func.func @test_full_pipeline(%arg0: memref<2x3xf32>, %arg1: memref<3x4xf32>, %arg2: memref<2x4xf32>) -> memref<2x4xf32> {
// ... 중략 ...
linalg.matmul ins(%3, %2 : ...) outs(%alloc : memref<2x4xf32>)
%4 = bufferization.to_tensor %alloc : memref<2x4xf32> to tensor<2x4xf32>
%5 = builtin.unrealized_conversion_cast %4 : tensor<2x4xf32> to memref<2x4xf32>
// onnx.Add가 구체적인 루프로 변환됨
krnl.iterate(%6#0, %6#1) with (...) {
%8 = krnl.load %5[%7#0, %7#1] : memref<2x4xf32> // MatMul의 결과 버퍼에서 로드
%9 = krnl.load %arg2[%7#0, %7#1] : memref<2x4xf32>
%10 = arith.addf %8, %9 : f32
krnl.store %10, %alloc_3[...] : memref<2x4xf32>
}
return %alloc_3 : memref<2x4xf32>
}
함수의 시그니처가 tensor에서 memref로 완전히 바뀌었습니다. 더 이상 추상적인 텐서는 존재하지 않습니다.
onnx.Add는 하드웨어가 이해할 수 있는 루프(krnl.iterate)와 로드/스토어(krnl.load, krnl.store) 연산으로 쪼개졌습니다.
unrealized_conversion_cast는 일시적인 타입 불일치를 해결합니다. 이는 나중에 최적화 패스에 의해 제거됩니다.
시리즈 포스트
Language: English
https://mlir.llvm.org/docs/Bufferization/ ↩