
[Paper Review]MaxEVA: AI Engine Kernel Placement Strategy and Communication Methods
Published:
The MaxEVA framework1 employs a sophisticated placement strategy that maximizes Versal AI Engine (AIE) array utilization and minimizes DMA (Direct Memory Access) usage in communication between MatMul kernels and adder trees, enhancing overall efficiency.
1. Kernel Group Configuration and Kernel Count
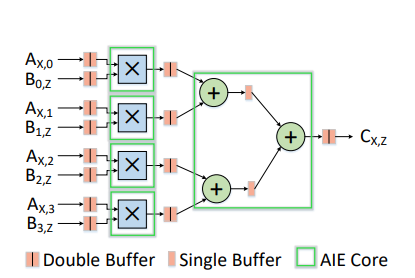
In MaxEVA’s mapping scheme, Y is a key parameter that defines MatMul kernel groups.
- The Y value determines the number of MatMul kernels (‘×’ symbol) within a group. For example, a group with Y=4 contains 4 MatMul kernels, each mapped to a separate AIE core.
- This group includes an adder tree (‘+’ symbol) consisting of Y−1 Add kernels, which are mapped sequentially to a single AIE core.
2. Inter-Kernel Communication Methods in AIE Array
Data movement and inter-kernel communication within the AIE array primarily occur through two methods. MaxEVA’s placement strategy focuses on utilizing direct memory sharing to avoid DMA usage.
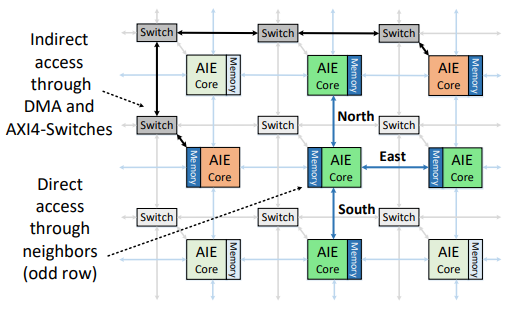
| Communication Method | Characteristics |
|---|---|
| Direct Memory Sharing | Adjacent AIE cores can directly access each other’s memory (32KB) |
| DMA (Direct Memory Access) / AXI4-Stream Switch | Used for communication between non-adjacent AIE cores, utilizing DMA mechanisms through programmable switches. This method has increased communication latency and requires more memory resources compared to direct access. |
3. Kernel Placement Techniques to Avoid DMA Usage
MaxEVA is designed so that when placing groups of Y MatMul kernels, the adder tree core can directly access the output buffers of adjacent MatMul kernels.
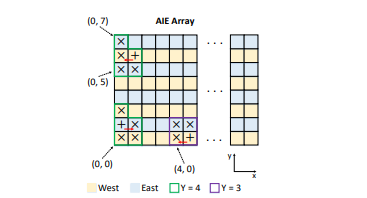
Placement Adjustment Example (0, 0 Group)
In an example of a Y=4 group, the adder tree core can directly access the memory of 3 out of 4 MatMul kernels. When direct access is difficult, as with the kernel at position (1, 0), that MatMul kernel’s output buffer can be placed at the northern position (1, 1), which is directly accessible by the adder tree, thus preventing DMA usage.
Row-Based Access Example (0, 5 Group)
Since AIE memory access varies by row (even rows access west, odd rows access east), the adder tree of the (0, 5) group can directly access only 2 out of 4 kernels. The output buffers of the remaining kernels at (0, 5) and (0, 7) are placed at positions (1, 5) and (1, 7), which are directly accessible by the adder tree, avoiding DMA.
4. Placement Patterns P1 and P2 for Filling the Entire AIE Array
MaxEVA proposes two patterns utilizing the kernel placement techniques presented in Section 3.
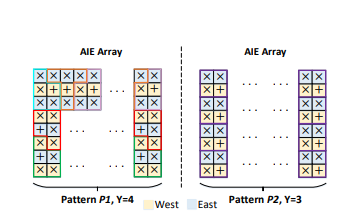
- Pattern P1: Uses a T-shaped form to fill 97.5% or more of the AIE array, which may result in minimal DMA usage from one MatMul output buffer.
- Pattern P2: Composed entirely of forms designed to completely avoid DMA usage, resulting in no DMA usage at all.
Language: 한국어 (Korean)
E. Taka, A. Arora, K. -C. Wu and D. Marculescu, “MaxEVA: Maximizing the Efficiency of Matrix Multiplication on Versal AI Engine,”International Conference on Field Programmable Technology (ICFPT), Yokohama, Japan, 2023, pp. 96-105, ↩